
 The primary use for Super Unicode Editor is to edit binary files that contain strings of Unicode characters in formats such as UTF-8, UTF-16, or UTF-32.
Super Unicode Editor can edit binary files like a regular hex editor, viewing each byte as its own character, regardless of the actual format. It can
also edit Unicode text files like a basic text editor such as Notepad. What makes Super Unicode Editor special is that it can decode various Unicode formats,
grouping together the bytes or words that form individual characters, with helpful visual clues such as underlining and color coding. Instead of a grid
of just bytes or 16-bit words, you can edit files with a grid of characters of varying length byte sequences.
The primary use for Super Unicode Editor is to edit binary files that contain strings of Unicode characters in formats such as UTF-8, UTF-16, or UTF-32.
Super Unicode Editor can edit binary files like a regular hex editor, viewing each byte as its own character, regardless of the actual format. It can
also edit Unicode text files like a basic text editor such as Notepad. What makes Super Unicode Editor special is that it can decode various Unicode formats,
grouping together the bytes or words that form individual characters, with helpful visual clues such as underlining and color coding. Instead of a grid
of just bytes or 16-bit words, you can edit files with a grid of characters of varying length byte sequences.

 Important tip about this help page: Many images are just thumbnails. When you move your mouse over these thumbnails and see the Enlarge arrow, simply
click the picture to display the full size image. Click the full size image to shrink it back to the thumbnail in order to read the text underneath it.
Important tip about this help page: Many images are just thumbnails. When you move your mouse over these thumbnails and see the Enlarge arrow, simply
click the picture to display the full size image. Click the full size image to shrink it back to the thumbnail in order to read the text underneath it.
[top]
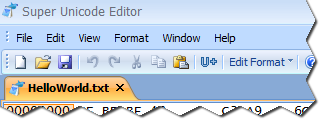 There is just one basic toolbar along with the menu bar by default in Super Unicode Editor.
There is just one basic toolbar along with the menu bar by default in Super Unicode Editor.
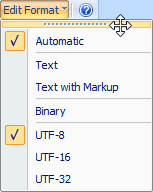 However, any menu or submenu in the program can be turned into a toolbar, by clicking and dragging the top of the menu in order to "tear-off" the menu.
However, any menu or submenu in the program can be turned into a toolbar, by clicking and dragging the top of the menu in order to "tear-off" the menu.

 The new toolbar will be a floating toolbar by default once you tear it off of the menu.
The new toolbar will be a floating toolbar by default once you tear it off of the menu.
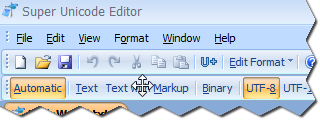 These new toolbars can be docked anywhere along side of the default toolbar and menu bar.
You may find it very useful to drag menus that you use often and create new toolbars from them, in order to reach the buttons quicker.
These new toolbars can be docked anywhere along side of the default toolbar and menu bar.
You may find it very useful to drag menus that you use often and create new toolbars from them, in order to reach the buttons quicker.
[top]
 The in-program help system contains the same help information that is available online, only it appears in a docking pane
that is by default docked to the right side of the window.
The in-program help system contains the same help information that is available online, only it appears in a docking pane
that is by default docked to the right side of the window.
You can show the help pane by selecting the help button
 on the Standard Toolbar. This pane can be resized by dragging the edge,
on the Standard Toolbar. This pane can be resized by dragging the edge,
 or set to auto-hide or be closed using the two buttons in their top right corner
or set to auto-hide or be closed using the two buttons in their top right corner
 .
You can move the panes around by dragging the title bar
.
You can move the panes around by dragging the title bar
 or tab
or tab
 of the panes. The panes can be docked to any side of the window, or left
floating above the entire program; however you would like to use them.
of the panes. The panes can be docked to any side of the window, or left
floating above the entire program; however you would like to use them.
[top]
The Standard Toolbar contains buttons to create new files, open existing files, and save opened files
 ,
edit files
,
edit files
 ,
open the Unicode Character Information pane
,
open the Unicode Character Information pane
 ,
change the edit format
,
change the edit format
 ,
and open the help pane
,
and open the help pane
 .
.
The default edit format is based on the format of the file being read, which uses automatic detection such as Byte Order Marks (BOM)
to determine the file format. Newly created, blank files default to the Binary edit format.
More details about each of the sections of buttons on the Standard Toolbar are explained below, in other help sections. The Help pane is explained above.
[top]
Super Unicode Editor can read files in a variety of Unicode formats, and can even change the format on the fly without doing any conversion. Files are read into memory
as a series of bytes, and those bytes in memory are interpreted based on the read format selected under the Format / Read Bytes As menu. A description of each
format is given below. Remember that changing the read format will not change the document bytes in memory in any way. It simply reinterprets the existing bytes
under the new format.
Automatic
The Automatic read format will select a format based on the first 2-4 bytes of the file. UTF-8, UTF-16, and UTF-32 can all be detected with the presence of a
Byte Order Mark (BOM) at the start of the file. Many text files will contain such a mark to make autodetection easier. The BOM will also identify if the file is
Little Endian or Big Endian. Without a BOM, Super Unicode Editor will check for <? and <! to identify HTML and XML files as UTF-8 (as is common, but not always the
case). Binary executable files and DLLs are identified by the 'MZ' header and will use the UTF-16 read format.
If the format can not be determined by the first 2-4 bytes of the file, the default will be to read it as Codepage 1252 (Latin-1). Editing a file and changing
the first few bytes will not cause the read format to be changed if Automatic is selected. The format is only set when you first open the file or specifically
select the Automatic read format option. Because newly created documents are completely blank, the default format will be Codepage 1252. You may want to change
this before adding to a new file, if you wish to use a different format.
Codepage
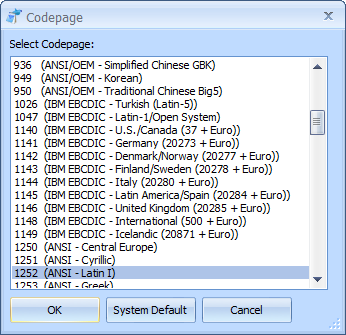 Selecting the Codepage read format will present a screen where you can select the specific Codepage to read the bytes as. As codepages are not true Unicode
formats, they generally can only store a handful of Unicode characters, specific to the language that the codepage corresponds to.
Selecting the Codepage read format will present a screen where you can select the specific Codepage to read the bytes as. As codepages are not true Unicode
formats, they generally can only store a handful of Unicode characters, specific to the language that the codepage corresponds to.
When reading a file as a specific codepage, the default edit format will be set to Binary, which only displays basic ASCII characters in the right-hand column.
You may want to select a different edit format, but keep in mind that many Unicode code points will not map to any valid character in the codepage and may be
translated to '?' instead. More information about the various edit formats are given below, in their own section.
UTF-8
The UTF-8 format supports reading sequences up to 6 bytes long, which allows 31-bit values, even though Unicode 6.0 defines that no value will be larger
than U+10FFFF. This allows better conversion between UTF-32. Valid code points will never be longer than 4 bytes. Super Unicode Editor will do it's best to read invalid
sequences by appending 0 bits when there are insufficient trailing bytes, and allowing extra trailing bytes to pass through. Overly long sequences such as C0 80
are also read in, which allows compatibility with Java serialization.
UTF-16
The regular UTF-16 format assume little endian encoding, which is typical of all Windows computers, and supports surrogate pairs for code point values up to the
full U+10FFFF. Loan surrogate pairs are read as individual code points that appear in the range reserved for surrogate pairs.
UTF-16 Big Endian
This format functions exactly like UTF-16, except bytes are read in big endian order to form the 16-bit words.
UTF-32
The UTF-32 format reads every 4 bytes as a single Unicode code point, allowing all values in the entire 32-bit range. This format assumes the little endian encoding order.
UTF-32 Big Endian
This format functions exactly like UTF-32, except bytes are read in big endian order to form the 32-bit words.
Source Code
The Source Code format functions like UTF-8 to start with, except strings are parsed for escape codes to form editable Unicode characters. Strings can begin and end with
either " or '. Escape codes begin with a \ character and can be followed by any of the following letters: z, a, b, t, n, v, f, r, e, or the characters \, ", or '.
Octal notation \0 through \377 can be read in, as well as \x00 through \xFF hexadecimal notation, for U+0000 through U+00FF code points. \u Unicode notation for U+0000
through U+FFFF and \U for U+10000 through U+10FFFF are also translated.
[top]
Every format that Super Unicode Editor can read, Super Unicode Editor can also convert entire documents into, by selecting the menu items under Format / Convert Bytes To. See the section
above for details about each format. Remember that certain formats can only represent certain ranges of character code points. For example, UTF-16 cannot represent
code points above U+10FFFF. For all valid code points, this is not an issue when you are converting to any Unicode standard format (UTF-8, UTF-16, or UTF-32).
Invalid code points that are out of the range for the format you are converting to will be changed to U+FFFD (The Unicode Replacement Character).
When converting to a codepage, any character that the codepage cannot represent will be changed into a '?' character. Codepages generally can only represent basic
ASCII characters and a handful of other characters specific to the language the codepage corresponds to.
When the document is converted to another format, the read format will be changed to match the new format automatically.
[top]
The edit formats in Super Unicode Editor closely correspond to the read formats. The choices are available under the Format menu as well as on the Standard Toolbar.
Details about each edit format are given below. Documents do not need to be edited in the same format that they are read as. For example, you can read a UTF-8
document as UTF-8, but edit it with the UTF-16 editor. Bytes are translated automatically behind the scenes as they are edited.
Automatic
The Automatic edit format will select an edit format based on the read format. Files read with a codepage will be edited in Binary mode. UTF-8 and Source Code formats
will be edited as UTF-8. Both UTF-16 and UTF-16 Big Endian share the UTF-16 edit format, which displays 16-bit words as single units, making endianness not an issue
when editing. Similarly, UTF-32 and UTF-32 Big Endian share the UTF-32 edit format.
Text
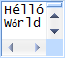 This format displays the entire document as plain text, similar to how Notepad would display and edit it. Unlike Notepad, editing in this format is binary-safe, which means
you can edit text without altering any other part of the file. There are no automatic conversions of new lines done by simply using this edit format. Not every character
can be typed in this format, because certain control characters aren't typable, but all Unicode code points at and above U+0020 should be typable.
This format displays the entire document as plain text, similar to how Notepad would display and edit it. Unlike Notepad, editing in this format is binary-safe, which means
you can edit text without altering any other part of the file. There are no automatic conversions of new lines done by simply using this edit format. Not every character
can be typed in this format, because certain control characters aren't typable, but all Unicode code points at and above U+0020 should be typable.
Some notes about editing files as text: Pressing Enter will insert both a CR and a LF character. Deleting a character will delete all combining characters attached to it as
one single unit, as will overwriting a character. This includes CR+LF as a single combined character when they appear together. Combining characters are rendered in the
editor as a single character, similar to how most other programs would render the text.
Text with Markup
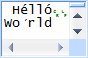 Text with Markup displays text like the regular Text format, except all code points are rendered as discrete units. Combining characters appear by themselves, next to the
characters that they would combine with. CR and LF are shown as individual characters that can be edited just like any other character. All control characters are also
displayed as editable characters. Lines are still separated by LF characters, even though the LF character is displayed as an actual character.
Text with Markup displays text like the regular Text format, except all code points are rendered as discrete units. Combining characters appear by themselves, next to the
characters that they would combine with. CR and LF are shown as individual characters that can be edited just like any other character. All control characters are also
displayed as editable characters. Lines are still separated by LF characters, even though the LF character is displayed as an actual character.
Binary


The Binary edit mode is exactly what just about every other hex editor program forces you to edit in. Each byte is displayed as two hexadecimal numbers grouped together
on the left column of the editor. The same byte is also rendered as a printable character (in the current system codepage, such as Latin 1) in the right column of the
editor. The hexadecimal index of the first byte of each row is given in the orange label box on the far left.
UTF-8
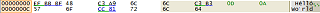
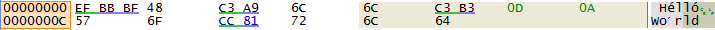
The UTF-8 editor format is similar to the Binary format, except UTF-8 sequences are grouped together as single units, and the grid is arranged to make room for the longest
UTF-8 sequence that appears in the document. This may cause some blank space to appear between many shorter UTF-8 sequences. Characters in the right column are rendered
as the proper Unicode code point given by the UTF-8 sequence of bytes. Valid UTF-8 sequences will be underlined in the left column, with the lead byte in green, and each
trailing byte in blue.
UTF-16


The UTF-16 format displays units of 4 hexadecimal numbers in the left column, allowing for values from 0000 to FFFF. Almost all common code points have a one-to-one
mapping to a single 16-bit value. For code points in the U+10000 to U+10FFFF range, two 16-bit values are combined to form a single code point. This is known as a
surrogate pair in the UTF-16 encoding. Valid surrogate pairs will be displayed as a single unit, with a green underline under the first 16-bit word, and a blue underline
under the second word. This will cause a blank space to appear in the right column in order to keep the two columns lined up. The orange label box on the far left
displays the index of the first word of the row, counting up by each 16-bit word. These numbers will only match the character count if there are no surrogate pairs in
the document, since surrogate pairs take up two words for one character.
UTF-32
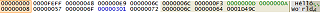

The UTF-32 editor format is one of the simplest, because there are no lead and trail bytes, no surrogate pairs, and all valid code points can easily be represented by
the same size word. Each 32-bit word is displayed as 8 hexadecimal numbers in the left column, and rendered as the corresponding Unicode code point in the right column.
[top]
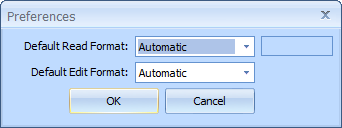 The Preferences window is available from the Edit / Preferences menu option. Here you can set the default read and edit format for all newly created or opened
files. The default is to try to automatically detect the file format, but if autodetection does not work on the majority of files you edit with Super Unicode Editor, then
you can set a different format here. If you select Codepage for the default read format, you will see the Codepage selection screen, and the codepage number will
be entered into the box to the right of the read format dropdown.
The Preferences window is available from the Edit / Preferences menu option. Here you can set the default read and edit format for all newly created or opened
files. The default is to try to automatically detect the file format, but if autodetection does not work on the majority of files you edit with Super Unicode Editor, then
you can set a different format here. If you select Codepage for the default read format, you will see the Codepage selection screen, and the codepage number will
be entered into the box to the right of the read format dropdown.
[top]
Super Unicode Editor uses a variety of color highlighting and underlining techniques to help visualize Unicode encoding and character types. The default is black text with
a white background.
Text Color
All control codes in the range U+0000 to U+001F as well as U+007F are displayed in green. In any text edit mode, as well as in the right column of other edit
modes, these green symbols are also displayed using the U+2400 range replacement pictures, which will show 2-3 very small letters that help identify the code point.
For example, U+000A (line feed) is displayed as a very small LF that only takes up 1 character in the grid.
All code points which are defined by Unicode as combining characters are displayed in blue. These code points typically combine with the previous code point to form
one single character. For example, U+0301 is the Combining Acute Accent and will add a ' mark on top of the previous character. Unicode may define single characters
such as U+00C1 which should be functionally the same as the letter A followed by U+0301. Highlighting combing characters in blue helps visualize what groups of
code points may join to display a single character when the document is viewed in the text edit mode or by other programs.
Sometimes, the code point is out of the range of valid code points, and the character displayed in the right column show a red question mark in a diamond shape.
Generally, any seemingly valid encoding of UTF-8 or UTF-32 that produces values above U+10FFFF will display this.
Underline
Green and blue underling is used to show which bytes or words form one single code point. Very common for UTF-8 for any code point above U+007F, but also used for
UTF-16 surrogate pairs. The lead byte or word is underlined in green, and all trailing bytes or words are underlined in blue.
Red wavy underlines denote encoding problems. Any value above U+10FFFF, any mismatch in the number of UTF-8 trailing bytes, or any mismatched UTF-16 surrogate pair
will be underlined like this. UTF-8 sequences that are not in their shortest form will also be underlined with a red wavy underline, such as C0 80 instead of
just 00 for the null character.
Background
The background is usually a grid of white and tan colors, helping to visualize every 4th row and 4th column of characters. One of the two overall columns in the editor
will be darker than the other, to show that the caret is currently focused in the other column. The exact character that the caret is on will have a light yellow
background.
Moving the mouse over characters will cause the background to change to orange. Both the left and right column in the editor will show the same character with the
orange background, as a visual cue to link the two columns together.
If there is any selected text, it will be highlighted with a light blue background. The opposite column will also highlight the same text with a slightly darker
blue background.
[top]
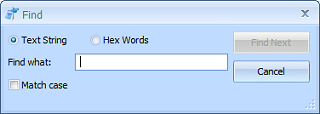
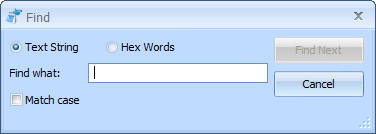 The Find window works just like you'd expect it to, similar to how it works in many other text editors. It is available under the Edit menu, or by pressing Ctrl+F.
The window will float above the editor, so it can be left open while small changes are made to the document. Finding text will match case sensitive only if the
Match case option is checked. Searching for text is somewhat like searching for what is displayed in the right side column of the editor.
The Find window works just like you'd expect it to, similar to how it works in many other text editors. It is available under the Edit menu, or by pressing Ctrl+F.
The window will float above the editor, so it can be left open while small changes are made to the document. Finding text will match case sensitive only if the
Match case option is checked. Searching for text is somewhat like searching for what is displayed in the right side column of the editor.
If you select to match Hex Words instead of a Text String, then the searching operates a little differently. You can only enter 0-9, A-F, and spaces into the
string to search for. Each hexadecimal word will be matched against one word in the editor. This option is somewhat like searching for what is displayed in the left
side column of the editor. In some edit modes (such as UTF-8 and Binary), each word you enter into the text to search for will correspond to one byte. This means
if you try to search for values greater than FF, such as 100, nothing will ever match.
In other edit modes, a word corresponds to a 16-bit or 32-bit value. The Text and Text with Markup modes will search for words in UTF-16 format, because that is the
format Windows uses internally for all text. The Match case option does not apply when searching for Hex Words. Each word must match the exact value in the document.
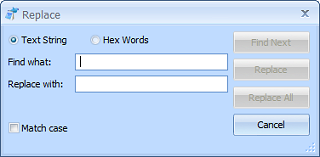
 The Replace window extends the Find window by adding the second text box to enter a replacement string, which can be left blank. Clicking the Replace button will
only replace the current selection if it actually matches what is being searched for. The next match will be highlighted after the replace operation, just like
clicking Find Next.
The Replace window extends the Find window by adding the second text box to enter a replacement string, which can be left blank. Clicking the Replace button will
only replace the current selection if it actually matches what is being searched for. The next match will be highlighted after the replace operation, just like
clicking Find Next.
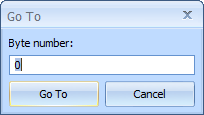 The Go To option, available under the Edit menu, is similar to Find, except that you just directly enter the byte, word, or line number you wish to jump directly to.
The caret will be moved immediately to the position entered.
The Go To option, available under the Edit menu, is similar to Find, except that you just directly enter the byte, word, or line number you wish to jump directly to.
The caret will be moved immediately to the position entered.
[top]
Copy and paste function in a pretty predicable manner. There are some important details to keep in mind if you wish to copy and paste between other programs, or
after changing the edit format.
Copy (and Cut)
Data it copied to the clipboard in a binary format that corresponds to the current edit format, not the document (Read Bytes As) format. For Text and UTF-16 formats,
this means the clipboard will contain little endian 16 bit words in a binary format. For UTF-32, every 4 bytes of the binary data placed on the clipboard will correspond
to one character.
An additional text format version of the data is also placed on the clipboard, for interaction with other programs that only accept text formats. The Binary and UTF-8
formats place ASCII text on the clipboard, byte for byte as it appears in the editor. The Text and UTF-16 edit formats place Unicode text on the clipboard instead.
If you are editing in the UTF-32 mode, no additional text format will be copied to the clipboard.
Paste
Pasting data will prefer to use the binary format, if available. This data will always be available in the copy was done from Super Unicode Editor. If you copied data to the
clipboard from another program, chances are it will only be in a text format. Super Unicode Editor will attempt to use this text from the clipboard, unless you are editing as
UTF-32. ASCII text will be read from the clipboard for Binary and UTF-8 modes, while Unicode text will be requested from the clipboard in Text and UTF-16 modes.
If the binary data is pasted from the clipboard, and it was copied to the clipboard while in a different edit mode, then the paste may or may not be what you intended.
This effectively re-interprets one Unicode format's raw byte stream as a different format.
[top]
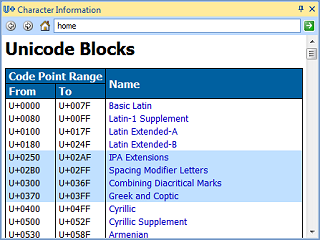
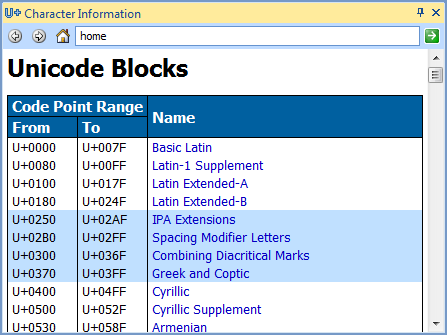 The Character Information pane is accessible on the Standard Toolbar
The Character Information pane is accessible on the Standard Toolbar
 as well as under the View menu, or by press Ctrl+U.
as well as under the View menu, or by press Ctrl+U.
This docking pane functions like a mini web browser with lots of detailed information about each Unicode code point, as well as the groups of code points referred to
as blocks. Code points and blocks can be explored without any open document. There are links to drill down into the blocks and individual code points, and the navigation
buttons at the top can be used to go back and forth between pages.

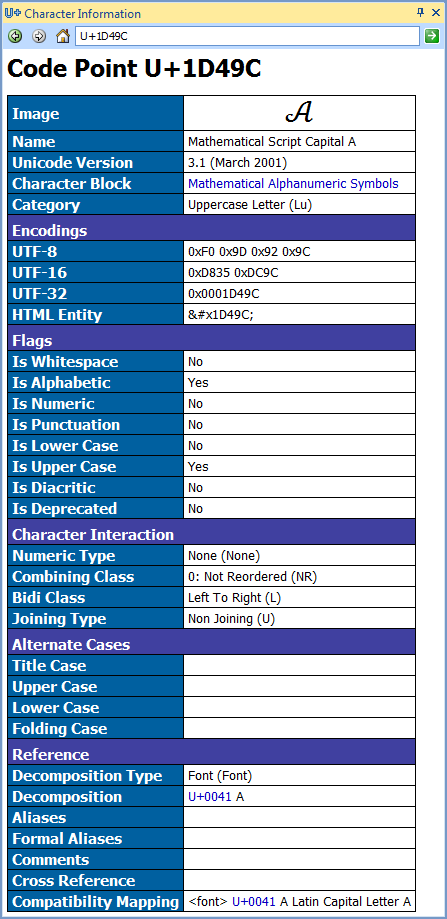 With an open document, every time the caret is moved, the Character Information window will be updated to display the character under the caret automatically.
With an open document, every time the caret is moved, the Character Information window will be updated to display the character under the caret automatically.
Many types of detailed information are given for every code point defined by Unicode, such as the encoding in various formats including HTML, information about how the
code point combines with other code points, and various transformations with links to other code points.
[top]
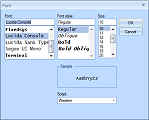
 The font used for the main editor window can be changed by selecting Font from the Format menu. Only fixed-width fonts can be selected, as the characters must be aligned
in a grid for Super Unicode Editor to function properly.
The font used for the main editor window can be changed by selecting Font from the Format menu. Only fixed-width fonts can be selected, as the characters must be aligned
in a grid for Super Unicode Editor to function properly.
A few other fonts will be used for certain symbols in the editor. They will always be the same size as the primary font you select. The symbols for control characters,
displayed in green in the right column of the editor, will use the first available font from Segoe UI Symbol, Arial Unicode MS, or Lucida Sans Unicode. Segoe fonts come with
Windows Vista or higher, and look the best. Arial Unicode MS comes packaged with many versions of Microsoft Office, and also looks good. If you are running on Windows XP
with no Office installed, the only font which contains these symbols is Lucida Sans Unicode. The symbols may exceed their grid boundaries and are not as visually crisp as
in other fonts.
Replacement characters for invalid code points, displayed in red in the right column of the editor, will use Microsoft Sans Serif on Windows Vista or higher, and will fall back
to Arial Unicode MS on Windows XP. If this font is not found, the replacement character symbol will not be displayed, as no other font has that glyph available.
[top]
Working with multiple views of the same file is one of the great features of Super Unicode Editor that separates it from other editors. Each view can have its own edit mode, as
well as each view can be scrolled to a different location in the document. Every view of the same document is updated automatically if any other view is edited, even
if the views use different edit formats.

 The simplest way to obtain multiple views is to use the window splitter. Click and drag on the split bar at the top of the scroll bar to create a second view.
The simplest way to obtain multiple views is to use the window splitter. Click and drag on the split bar at the top of the scroll bar to create a second view.

 By default, the new view will be a copy of the old view, so both appear the same. You can also select Split from the Window menu to split the window into two
views, stacked one on top of the other.
By default, the new view will be a copy of the old view, so both appear the same. You can also select Split from the Window menu to split the window into two
views, stacked one on top of the other.

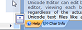
 In this picture, the bottom view was changed from the UTF-8 edit mode to UTF-16, and the mouse cursor is hovering over the ó. You can see how the bytes and words
that correspond to that character are highlighted in both views. Editing that character in either view will automatically display the proper encoding of bytes or words
in the opposite view.
In this picture, the bottom view was changed from the UTF-8 edit mode to UTF-16, and the mouse cursor is hovering over the ó. You can see how the bytes and words
that correspond to that character are highlighted in both views. Editing that character in either view will automatically display the proper encoding of bytes or words
in the opposite view.

 Another way to obtain multiple views of the same document is to select the New Window option from the Window menu. This will create an entire cloned tab of the document.
Each view is denoted by a number after the colon at the end of the file name in the tab such as :1 and :2. You can drag the tab to create split views horizontally or
vertically, or select one of the Tile options from the Window menu to give every tab its own area.
Another way to obtain multiple views of the same document is to select the New Window option from the Window menu. This will create an entire cloned tab of the document.
Each view is denoted by a number after the colon at the end of the file name in the tab such as :1 and :2. You can drag the tab to create split views horizontally or
vertically, or select one of the Tile options from the Window menu to give every tab its own area.

 In this example, the second view was changed from UTF-8 to UTF-16, and the mouse is hovering over the ó character again. There is no limit to the number of
new windows you can create of the same document, and each window can also use the window splitter at the same time to obtain more views. Closing one of the tabs will
not close the document until the last tab is closed.
In this example, the second view was changed from UTF-8 to UTF-16, and the mouse is hovering over the ó character again. There is no limit to the number of
new windows you can create of the same document, and each window can also use the window splitter at the same time to obtain more views. Closing one of the tabs will
not close the document until the last tab is closed.
[top]
All of the regular editor windows in Super Unicode Editor are always maximized and shown on a tab bar. The windows can be separated into
groups of tabs, and each group has left and right buttons
 to move through the tabs when many windows are open at once.
to move through the tabs when many windows are open at once.
 The close button appears on the tab of any visible editor window.
The close button appears on the tab of any visible editor window.
 The window tabs can be clicked and dragged for reordering, or they can be dragged to other groups. Drag a tab to the edges of a group to split the
group in half, creating a new group.
The window tabs can be clicked and dragged for reordering, or they can be dragged to other groups. Drag a tab to the edges of a group to split the
group in half, creating a new group.
Because all windows are always maximized with the tab groups, the Tile Horizontally and Tile Vertically options under the Window menu will function
to set each open window into its own group, while Cascade will place all open windows into one single group. You can still select a window for focus
from the Window menu, but clicking on the tabs in the tab bar has the same effect.
The window's skin can be changed between Office 2007 and the native OS look by selecting View / Use Skin.
The functionality of the program is not affected by the skin, although there may be less visual cues for hovering or dragging effects without it.
[top]
Many things that can be done in Super Unicode Editor by using the mouse can also be done with keyboard shortcuts
or other alternative methods.
| Ctrl+N |
Create a new, blank document |
| Ctrl+O |
Open an existing file of any type |
| Ctrl+S |
Save the currently opened file |
| Ctrl+Z |
Undo the last edit |
| Ctrl+Y |
Redo the last undone edit |
| Ctrl+X |
Cut the selection |
| Ctrl+C |
Copy the selection |
| Ctrl+V |
Paste from the clipboard |
| Delete |
Delete the selection |
| Ctrl+F |
Find |
| F3 |
Find Next |
| Ctrl+H |
Replace |
| Ctrl+G |
Go To |
| Ctrl+A |
Select All |
| Ctrl+D |
Select None |
| Arrow Keys |
Move the caret around |
| Insert |
Toggle between insert and overwrite mode |
| Tab |
Toggle focus between binary and text columns |
| Home |
Move the caret to the start of the row |
| End |
Move the caret to the end of the row |
| Ctrl+Home |
Move the caret to the start of the document |
| Ctrl+End |
Move the caret to the end of the document |
| Page Up |
Move the caret up one screen |
| Page Down |
Move the caret down one screen |
| Ctrl+U |
Show Character Information pane |
| F6 |
Toggle focus between split panes |
| Ctrl+F6 |
Switch to the next editor window |
| Ctrl+Shift+F6 |
Switch to the previous editor window |
| F1 |
Show help pane |
[top]
If you have come to this point and still have questions or would like to suggest a feature, feel free to
visit our support forums
and we will do our best to assist you in making your experience with Super Unicode Editor a great one.
Thank you for using Super Unicode Editor.
[top]
 17. Additional Help
17. Additional Help